
Page 21 - 防禦還是破口?辨識AI的安全威脅
P. 21
得問題變得更加複雜。近來,人們 對於使用對抗式學習(adversarial learning)以創造更先進複雜的 混淆技術之研究興趣日益增加, 例如形變混淆(metamorphic obfuscation),其中被混淆的惡 意軟體功能與原始惡意軟體的功 能相同。
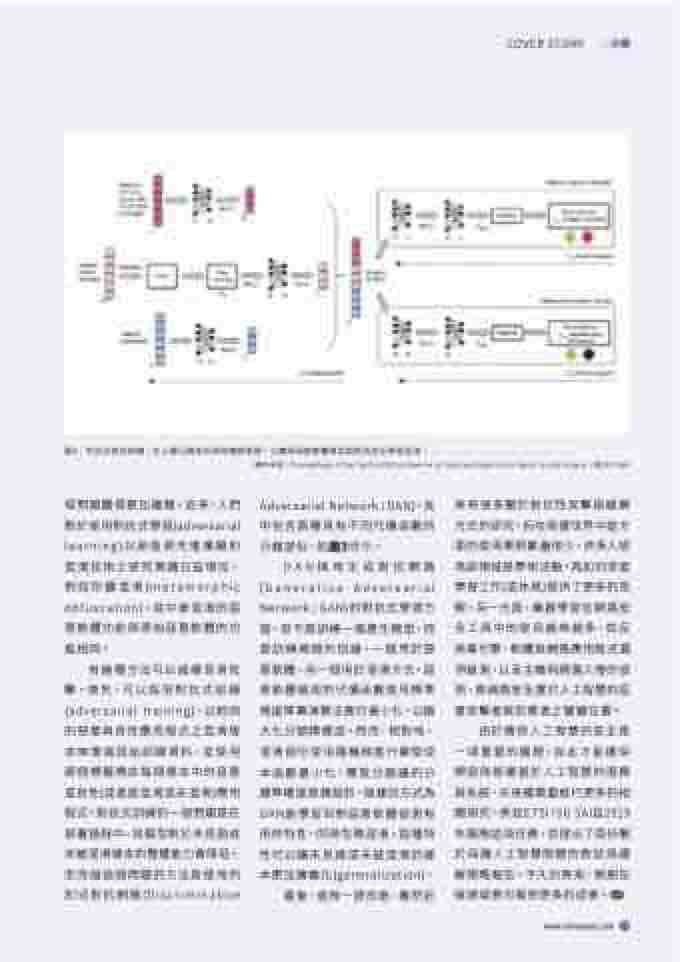
Adversarial Network;DAN),其 中包含兩種具有不同代價函數的 分類部份,如圖3所示。
來有很多關於對抗性攻擊與緩解 方式的研究,但在現實世界中這方 面的使用案例數量很少,許多人認 為該領域是學術活動,為如何深度 學習工作(或休息)提供了更多的見 解。另一方面,機器學習在網路安 全工具中的使用越來越多,如反 病毒引擎、軟體與網路應用程式漏 洞檢測,以及主機與網路入侵的偵 測,將網路安全置於人工智慧的惡 意攻擊者與防禦者之關鍵位置。
有幾種方法可以減緩混淆攻 擊。首先,可以採用對抗式訓練 (adversarial training),以相同 的惡意與良性應用程式之混淆版 本來增強原始訓練資料,並使用 兩個標籤標註每個樣本中的惡意 或良性(或者是混淆或未混淆)應用 程式。對抗式訓練的一個問題是在 部署過程中,其模型對於未見過或 未被混淆樣本的整體能力會降低。 而克服這個問題的方法是使用判 別式對抗網路(Discriminative
DAN採用生成對抗網路 (Generative Adversarial Network;GAN)的對抗式學習方 面,但不是訓練一個產生模型,而 是訓練兩個判別器,一個用於惡 意軟體,另一個用於混淆方式。惡 意軟體檢測的代價函數使用標準 梯度降冪演算法進行最小化,以極 大化分類精確度。然而,相對地, 混淆部份使用隨機梯度升冪使成 本函數最小化,導致分類器的分 類準確度是偶發的。這樣的方式為 DAN能學習到對惡意軟體偵測有 用的特性,同時忽略混淆。這種特 性可以讓未見過或未被混淆的樣 本更加廣義化(generalization)。
由於確保人工智慧的安全是 一項重要的議題,如此才能確保 開發與部署基於人工智慧的服務 與系統,未來還需要進行更多的相 關研究。例如ETSI ISG SAI自2019 年展開這項任務,並提出了兩份關 於保護人工智慧問題的敘述與緩 解策略報告。不久的將來,預期在 這領域將可看到更多的成果。
最後,值得一提的是,雖然近
COVER STORY
圖3:判別式對抗架構,在上層分類部份採用傳統學習,以實現惡意軟體偵測與對抗性反學習混淆。
(資料來源:Proceedings of the Tenth ACM Conference on Data and Application Security and Privacy,頁353-364)
www.edntaiwan.com 19
